
「LLMとRAGを組み合わせると、生成AIの回答がより正確になると~聞いたけれどどういうこと?」
「コンタクトセンターに生成AIの機能を導入したいけれど、「まだ回答に間違いが多い。LLMとRAGの併用でそれが改善されるって本当?」
この記事を読んでいるあなたは、生成AIについてこのような疑問を持っているのではないでしょうか。
「LLM(Large Language Model)」と「RAG(Retrieval-Augmented Generation)」を組み合わせることで、生成AIの精度を高めることが可能です。
「LLM」は、大量のテキストを学習し、自然言語処理に優れたAIです。しかしながら、学習したデータに依存するため、未学習の情報については正確な回答を出すことが難しいという弱点があります。
この弱点を補うのが「RAG」です。
RAGはLLMが学習していない最新の情報や社内情報などを外部のデータベースから検索し取得することが可能であり、これによりLLM単体では対応困難な質問にも正確に回答することができます。
【LLM+RAGのイメージ】
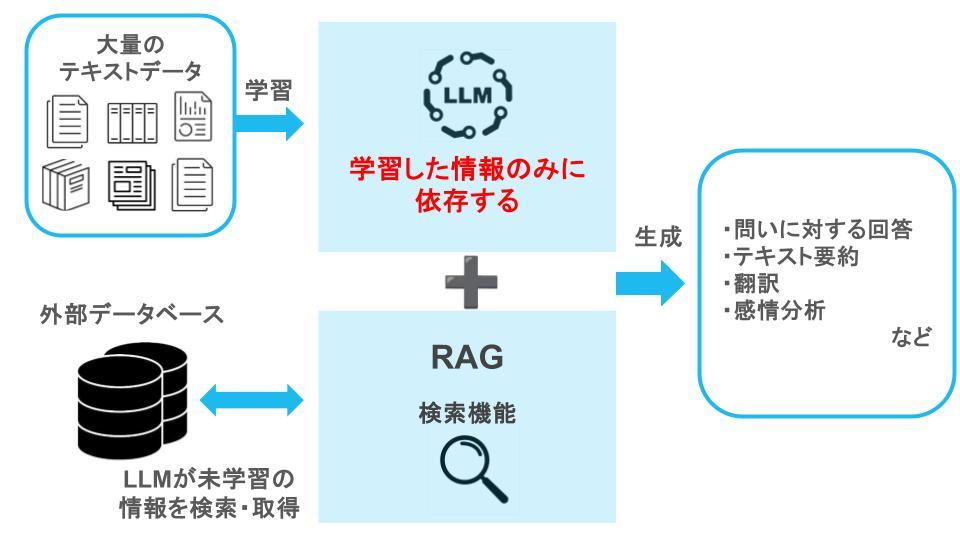
「LLM+RAG」によって、以下のことができるようになります。
・生成AIの回答精度向上 |
そのため、以下のようなシーンで活用することが可能です。
・問い合わせ対応 |
この記事では、注目を集めている「LLM+RAG」についてわかりやすく説明します。
◎「LLM+RAG」とは? |
最後まで読めば、生成AIの最新事情について理解できるでしょう。
この記事で、生成AIを効果的に活用する手助けとなれば幸いです。
1.「LLM+RAG」とは?

生成AIの精度向上と利便性向上を図るために注目されているのが、「LLM(Large Language Model)」と「RAG(Retrieval-Augmented Generation)」の組み合わせです。
では、「LLM+RAG」とは具体的にどのようなものなのか、わかりやすく説明しましょう。
1-1.LLMとは
「LLM(Large Language Model)」は、大量のテキストを学習し、人間の自然言語処理能力を模倣したAIの一種です。日本語では「大規模言語モデル」と呼ばれます。
ディープラーニング技術を用いて膨大なテキストデータを学習することで、会話がスムーズに行えるだけでなく、テキストの要約・抽出、翻訳、感情分析などをより自然に行うことが可能となります。
【LLMのイメージ】
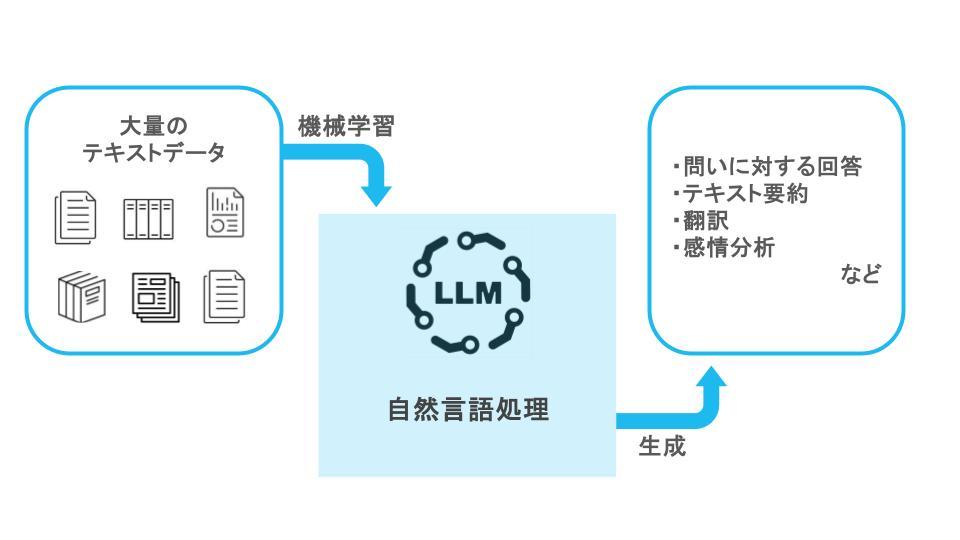
近年注目されている多くの生成AI、例えばChatGPTやGeminiなどでもこのLLMが用いられています。
ただ、LLMの処理能力は、学習したテキストデータに依存します。
そのため、学習済みの情報については詳しく回答することができますが、まだ学習させていない最新の情報や、特定の企業の社内規定などの広く公開されていない情報については適切な回答ができず、一般論での回答にとどまってしまう、というのが難点です。
1-2.RAGとは:ファインチューニングとの違い
一方「RAG」とは、「文書検索機能」と「生成AI」を組み合わせて、より精度の高い回答を生成可能にする技術です。
「Retrieval=検索」「Augmented=強化された」「Generation=生成」の頭文字をとった言葉で、日本語では「検索拡張生成」と呼ばれます。
LLMが事前に学習したデータのみに基づいて回答を生成するのに対して、RAGは外部のデータベースからリアルタイムで必要な情報を検索・取得して回答を生成することが可能です。
【RAGのイメージ】
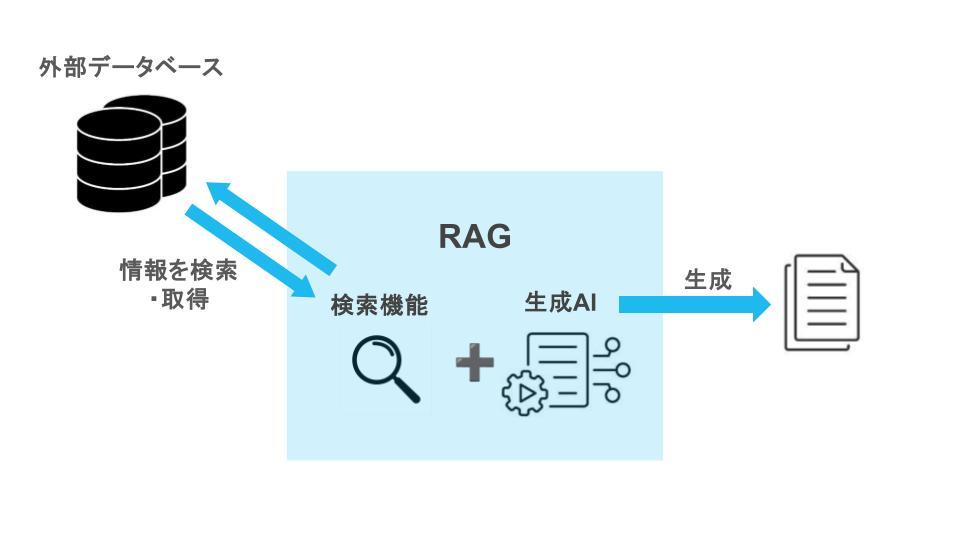
つまり、LLMの弱点である「最新情報など未学習の情報については正確な回答ができない」という点を、リアルタイムの検索で補うことができるというわけです。
ちなみに、RAGと同様に、LLMを未学習の情報にも回答できるようにする方法として「ファインチューニング」というものもあります。これは、既存の機械学習モデル自体に足りないデータを与えて学習させることで、目的の回答を得られるように調整する方法です。
それに対してRAGは、足りない情報をその都度外部から検索して持ってくるので、モデル(この記事の場合はLLM)には手を加える必要がありません。
人に例えれば、わからないことを新たに学んで本人自身の知識として身につけさせるのがファインチューニング、わからないことが出てくるたびに手近にある辞書や資料で調べて回答を得るのがRAG、と考えればいいでしょう。
1-3.「LLM+RAG」の組み合わせで生成AIの精度・効率が向上する
前項で述べたように、「LLM」に「RAG」を組み合わせることで、LLMの弱点である「学習した情報のみに依存する=未学習の情報に対応できない」という点を、外部データベースを検索することで補えるようになります。
その結果、現在の生成AIが抱える課題である以下の2点を解決することができ、生成AIの精度や効率の向上が期待できるでしょう。
【生成AIの課題】
・基本的には広く公開されている情報を学習しているため、非公開情報については正確な回答ができない |
この内容については、次章でさらに詳しく説明します。
例えば企業で「業務に生成AIを活用したい」と考えていても、「試しに使ってみたところ、回答の精度があまり高くなく、実用レベルには足りない」とか、「自社の新製品情報や、社内規定などについて生成AIは学習しておらず、それを学ばせるのは機密漏洩のリスクやコストの面で不安がある」といった理由で導入に踏み切れないケースもあるでしょう。
それらの問題をクリアして、生成AIをより精度高く効率的に活用できる方法として、近年この「LLM+RAG」に注目が集まっています。
1-4.「LLM+RAG」のしくみ
ここまでで、「LLM+RAG」の概要は理解いただけたかと思います。
ただ、さらに詳細な仕組みに興味を持つ方もいるでしょう。以下の図をご覧いただきながら、その仕組みを簡潔に説明します。
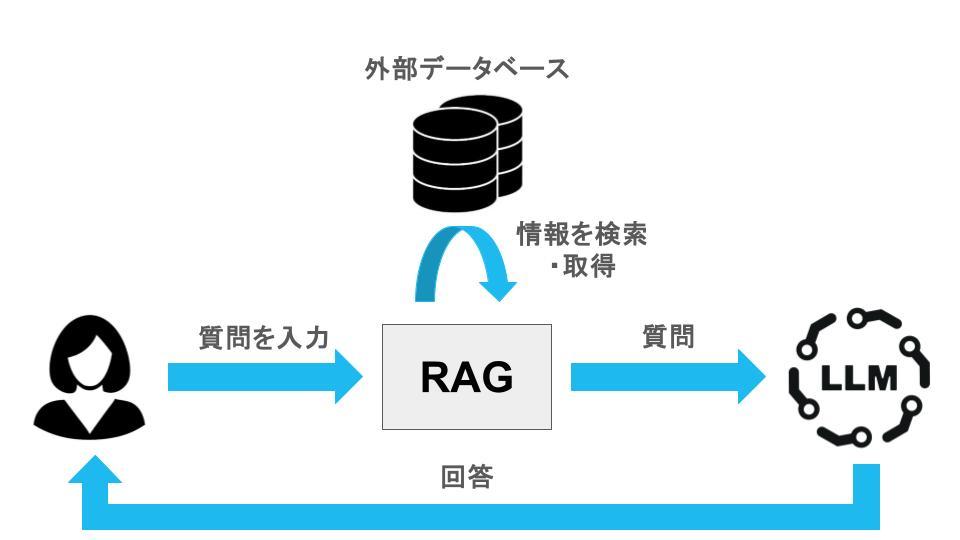
「LLM+RAG」のシステムに質問を入力すると、RAGの検索機能がその質問に関係する情報を外部のデータベースなどから検索して取得します。
その後、検索された情報を追加して、再度質問がLLMに送られます。LLMはその質問と検索結果を基にして、言語処理能力を活用して回答を生成します。このようにして、「LLM+RAG」は情報の検索と生成を組み合わせることで、より正確な回答を提供するしくみとなっています。
2.「LLM+RAG」でできること

前章で、RAGはLLMの弱点を補い、より精度の高い回答を効率的に得る方法について説明しました。
この章では、具体的に「どんなことができるのか」について詳しく見ていきましょう。
「LLM+RAG」の組み合わせによって実現できる主な機能は、以下の通りです。
・生成AIの回答精度向上 |
それぞれ説明します。
2-1.生成AIの回答精度向上
まず第一に、生成AIの精度が向上し、より広範囲で深い情報に基づいて回答できるようになります。
特に、生成AIが抱える「ハルシネーション(幻覚)」の発生頻度を減少させる点が大きな利点です。
LLM単体では、膨大な情報を機械学習し、それを基にテキスト生成や質問応答を行います。しかし、学習していない情報に対しては正確な回答が得られないという課題があります。
例えば、「◯◯のニュースについて」と質問した場合、もしLLMが学習したデータの中に適した情報が乏しければ、回答はあいまいになったり、表面的な内容に留まったりすることがあります。
また「ニュースとは」という一般論で回答したり、ハルシネーションを引き起こして存在しない架空のニュースを作り出してしまうこともあります。
その点、「LLM+RAG」の組み合わせを利用すれば、RAGがインターネットや外部のデータベースから広範な情報を検索・取得できます。これにより、正確で新しい情報を基にした回答生成が可能となり、ハルシネーションのリスクも低減されます。
2-2.社内データなど独自情報をもとに回答
また、社内データなど一般には公開されていない独自情報についても、正確な回答が得られるようになります。
一般的に、LLMは主にインターネット上に公開されているデータセットを用いて機械学習を行います。
逆に言えば、公開されていないクローズドな情報、例えば各企業の社内規約や、機密性の高い製品情報については学習していません。
そのため、「我が社の就業規則について」といった質問に関する情報は持たず、一般論的で回答したり、ハルシネーションによって誤った情報を提供したりするリスクがあります。
一方、「LLM+RAG」を活用すれば、社内規則に関するデータを用意しておくことで、正しい回答を生成できるようになります。また、参照するデータベースに利用制限を設けるなどのセキュリティ対策を講じることにより、機密性の高い情報の漏洩リスクを抑えることも可能です。
社内規則だけでなく、顧客情報や開発中の製品情報、業界ごとの専門文献など、必要な情報をデータベース化することで、LLM単体では回答できない社内情報や専門的な質問についても、RAGの検索機能を通じて精度の高い回答が得られるようになります。
2-3.最新情報の参照
さらに、LLMが学習していない最新情報についても、RAGを利用することで検索・参照し、適切な回答を生成できるようになります。
繰り返しになりますが、LLMは学習済みのデータに依存します。
機械学習後に更新された新しい情報は持っておらず、それに関しては正確な回答を生成することができません。
例えば、LLMが2024年1月までのデータセットを学習していている場合、2024年2月以降の情報については把握できないのです。
しかし、RAGを組み合わせることで、LLMが持っていない新しい情報をインターネットや外部のデータベースから検索・取得できます。その結果、LLMは最新情報を含めた回答を生成することが可能になります。
なお、LLM自体に定期的に最新情報を追加学習させることは可能ですが、それには多大なコストや工数がかかるのが難点です。
これに対して「LLM+RAG」を利用すれば、RAGがつねにリアルタイムで新しい情報を取得できるため、コストを抑えながらも最新情報を参照することが可能です。
3.「LLM+RAG」の活用事例

「LLM+RAG」で何ができるかが明らかになりましたが、実際の企業ではどのように活用されているのでしょうか?
この章では、主な活用シーンの例としてを4つのケースを挙げてみます。
・問い合わせ対応 |
3-1.問い合わせ対応
「LLM+RAG」の主な活用例として、問い合わせへの対応が挙げられます。
顧客からの問い合わせや社内問い合わせに対し、チャットボットのように迅速に回答することが可能です。
特にカスタマーサポートの分野では、回答用のデータベースとして製品情報やマニュアルだけでなく、顧客情報や過去の問い合わせ履歴も登録することで、顧客それぞれにパーソナライズされた対応が実現できます。
また、コンタクトセンター(コールセンター)においては、オペレーターが顧客への対応方法をリアルタイムで検索する使い方も効果的です。
問い合わせの種類に応じて、以下のような情報をデータベースに登録することで、適切な回答を期待できます。
【問い合わせ対応に必要なデータベースの例】
・カスタマーサポート : 製品情報、取り扱いマニュアル、FAQ、顧客情報、問い合わせ履歴など |
3-2.FAQの生成
問い合わせ対応と似た活用例として、FAQの生成も挙げられます。
過去の顧客からの問い合わせや、それに対する製品マニュアルなどをデータベース化することで、「LLM+RAG」がよくある質問とその回答を生成することができます。
適切なFAQをWebサイトなどに設置することで、顧客は電話やチャットで問い合わせを行わなくても、Web上で自分の問題を解決できるようになります。
顧客の利便性と満足度の向上が期待できるため、顧客ニーズに合ったFAQを作成することは非常に有効です。
ただ、FAQの数が少なかったり、顧客が知りたいこととズレていたり、顧客のニーズを満たしていない企業も多いのではないでしょうか。
その点「LLM+RAG」を活用すれば、顧客の問い合わせ履歴などのデータベースをもとに、多くの顧客が知りたい「Q」を抽出し、マニュアルから正しい回答を生成することが可能です。
これにより従来よりも顧客ニーズを満たすFAQの生成が期待できるでしょう。
3-3.社内情報の検索
「LLM+RAG」の中でも、特に「RAG」の検索機能に注目し、社内の資料や情報を管理、検索するケースが増えています。
企業によっては、社内の各部署に散在する資料をデータベース化し、閲覧できるようにしているところもあるでしょう。
しかし、膨大なデータの中から必要な資料を探すのは容易ではなく、「見つけた!」と思っても、内容を確認した結果、役に立たない資料であった場合、新たに別の資料を探すという手間も生じることがあります。
そこで、「LLM+RAG」を活用することで、膨大な社内情報を効果的に管理し、迅速に検索できるようになります。
社内規則、業務マニュアル、議事録、報告書、企画書など、さまざまな社内文書をデータベースとして統合すれば、「◯◯プロジェクトに関する資料を出して」といった一つの指示で、RAGによる横断的な検索が可能です。
さらに、LLMが資料の内容を要約してくれるため、大量の資料に目を通す時間と手間を削減することができます。
3-4.コンテンツの生成
「LLM+RAG」は、コンテンツ生成にも非常に適しています。
Webサイトに掲載する記事やプレスリリース、営業資料、取引先へのメール文など、さまざまな種類のコンテンツを生成することが可能です。
そもそもLLMだけでもコンテンツ生成は可能ですが、その場合、未学習の情報については正確に対応できなかったり、誤った内容を生成するリスクが存在します。
この弱点をRAGの検索機能で補うことで、より正確で質の高いコンテンツを作成することができるでしょう。
4.「LLM+RAG」の導入が向いている企業

このように、業務のさまざまなシーンで活用できる「LLM+RAG」ですが、自社に導入しても良いのだろうか?」と不安を感じる企業も多いのではないでしょうか。
実際のところ、「LLM+RAG」の導入が向いているのはどのような企業でしょうか?
代表的な例として挙げられるのが、「数回のやり取りで解決する質問が大量に寄せられる企業のコンタクトセンター(コールセンター)」です。
以下のような業種が特に適しています。
・金融 |
一問一答で迅速に答えられる問い合わせに対して、「LLM+RAG」は適切な回答を素早く提供することが可能です。
一方で、現状では「LLM+RAG」だけに問い合わせ対応させるのはあまり適していないケースもあります。
具体的には以下のような状況です。
・予約手続き、返品交換、再配達など、シナリオに基づく応対フローが求められる問い合わせ対応 ・トラブルシューティングやテクニカルサポートなど、複数のヒアリングを通じて解決が必要な問い合わせ対応 |
ただ、コンタクトセンター以外でも、「3-3.社内情報の検索」で触れたような使い方をするのであれば、どのような企業でも活用の余地はあるでしょう。
「LLM+RAG」の導入にご興味のある方は、 トランスコスモスでは、生成AIを業務に活用した企業向けに、コンタクトセンターへの「LLM」「RAG」導入をサポートしています。 問い合わせ対応の自動化をはじめ、FAQ生成、オペレーター支援などさまざまなシーンで業務を効率化し、顧客満足度の向上に貢献しますので、ぜひ一度お問い合わせください。 |
5.「LLM+RAG」導入の注意点

ここまで、「LLM+RAG」がいかに有用であるかを説明してきました。しかし、もちろん良いことばかりではありません。いざ導入するとなると、注意しなければならない点もいくつかあります。
そこで最後に、実際に導入する際に気を付けるべき注意点をいくつか挙げておきます。
・回答の精度を高めるには、チューニングとモニタリングを継続する必要がある |
これらの注意点を踏まえた上で、「LLM+RAG」を導入することを検討してください。
5-1.回答の精度を高めるには、チューニングとモニタリングを継続する必要がある
LLMは学習したデータに基づいてのみ回答を生成するため、足りない情報をRAGが外部から検索して補うという仕組みです。しかし、RAGの検索も万能ではありません。
もし、データベース内の情報が間違っていたり古かったりすれば、生成される回答も正確性を欠くことになります。
そのため、「LLM+RAG」を導入した後も、データベースの正確性を定期的にチェックし、必要に応じてチューニングを行うことが重要です。
さらに、生成されたテキストなどの内容もモニタリングし、間違いや不備が見つかった際にはその原因を特定し、解消するための継続的なメンテナンスが求められます。
5-2.機密情報の取り扱いには注意が必要
RAGを用いることで、一般に公開されていない情報もLLMが扱えるようになります。
逆に言えば、データベースに機密情報が含まれている場合、それがLLMの生成する回答に反映される恐れがあります。
もし、顧客からの問い合わせに対する回答に、社外秘や社内秘の情報が含まれてしまったら大変な事態になります。
このような情報漏洩リスクを避けるには、RAGが参照できるデータベースから機密情報を除外する、または機密情報に対してアクセス制限を設けるなど、情報の取り扱いには十分な注意が必要です。
5-3.精度が高まると、速度が遅くなる場合がある
RAGはその性質上、回答の精度を高めようとすると、反比例して処理速度が遅くなりがちです。
つまり、参照するデータ量が多くなるほど、検索にかける時間も長くなってしまいます。
社内問い合わせの場合、多少待ち時間があってもあまり気にならないかもしれませんが、顧客からの問い合わせの場合は、速度の遅さがユーザーエクスペリエンスの低下につながる可能性があります。
そのため、導入の際には「十分な速度が得られるのか」を事前に確認することが重要です。
5-4.データベースに画像やPDF、表形式などを含む場合、RAGが認識できない場合がある
RAGが参照する外部データベースを用意する際には、テキストデータだけでなく、画像やPDF、表なども含まれるケースもあるでしょう。その場合、RAGがこれらの非テキストデータをうまく認識できない可能性があるため、注意が必要です。
データが正しく認識されているかを確認し、もし問題があれば、認識できる形式に変換する必要があります。
5-5.オリジナリティのあるコンテンツ生成には向かない
「LLM+RAG」はコンテンツ生成が可能ですが、あくまで既存のデータに基づいています。
そのため、完全にオリジナルなコンテンツを生成するのは非常に難しいといえます。
独自性を求められない場合、例えば説明文やビジネスメール文などであれば、十分に活用できるでしょう。しかし、「これまでにない新しい企画を立てたい」とか、「オリジナルのストーリーを作りたい」といった場合は、やはり人の力が必要です。
独自性の部分は人間が考え、企画書作成やストーリー要約などの具体的な作業を「LLM+RAG」に任せるという使い分けが効果的です。
まとめ
いかがでしたか?
LLMとRAGについて、知りたいことがわかったのではないでしょうか。
ではあらためて、記事の要点をまとめておきましょう。
◎「LLM=大規模言語モデル」と「RAG=文書検索機能と生成AIを組み合わせて、より精度の高い回答を生成可能にする技術」をあわせて用いることで、生成AIの精度を高めることが可能
◎「LLM+RAG」でできること
・生成AIの回答精度向上 |
◎「LLM+RAG」の活用事例
・問い合わせ対応 |
◎「LLM+RAG」の導入が向いているのは、「数回のやりとりで解決する質問が大量に寄せられる企業のコンタクトセンター(コールセンター)」など
◎「LLM+RAG」導入の注意点
・回答の精度を高めるには、チューニングとモニタリングを継続する必要がある |
この記事で、あなたの会社が生成AIをうまく活用できるよう願っています。